
It’s been a while since my last machine learning project: implementing a decision tree in Julia. This time I wanted to take a closer look at neural networks. I was recently shown an amazing book 'Neural Networks and Deep Learning' by Michael Nielson. He does a great job distilling the basics to a point where his explanations become intuitive. I won't be able to explain anything as well as he does so please check out his book.
The most basic neural networks are, as it turns out, surprisingly simple. It is possible to derive methods for building and training neural networks using only basic linear algebra and calculus. Neural networks have also been around for quite some time but it wasn’t until backpropagation was suggested as a way of training networks in the 70's that they really took off. The complexity of them stems somewhat from the sheer size of networks. Modern computer hardware and new scientific computing methods were required for neural networks to reach the popularity they have today.
Backpropagation is the key to training neural networks. Essentially, backpropagation takes the error at the output of a network and updates weights, within the network, based on how much they contributed to that error. By calculating the error from a sample and adjusting the weights accordingly over many, many iterations the network can be trained.
So in keeping with my previous project, I implemented a basic backpropogation algorithm in C for training on the popular MNIST dataset. I used a combination of the GNU Scientific Library and OpenBLAS for all the heavy number crunching. For the network itself I went with 2 hidden layers (4 total, including input and output layers) of 100 and 30 neurons. Below is the result after training on 50,000 images:
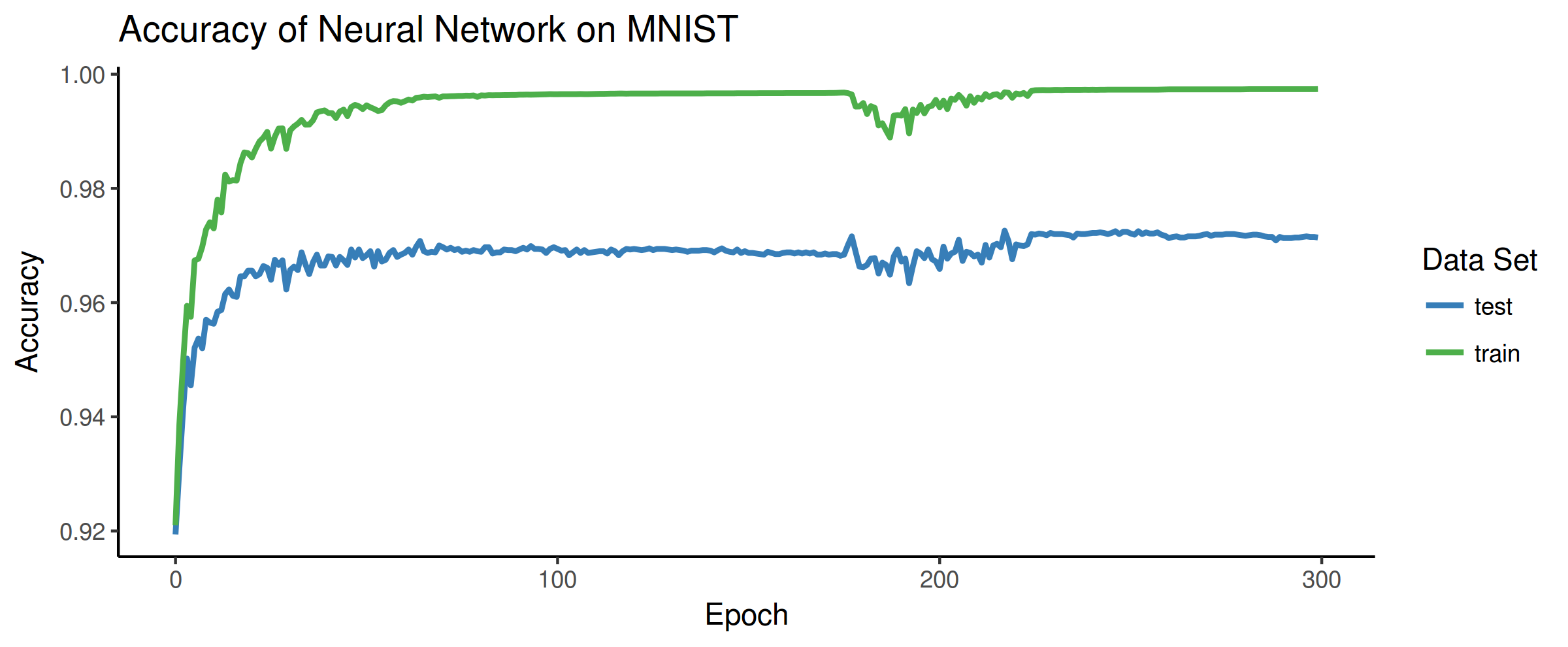
The green shows accuracy on training data and the blue shows the neural networks accuracy on a separate set of testing data. The x-axis shows the number of epochs, or the number of times the backpropagation went through all the training data and updated the network. Interestingly, after about 100 epochs the accuracy on the test data starts to decrease slightly. This is a sign that the network was overfitting to the training data. However, after around 180 epochs there is some disruption which ended up increasing the accuracy on both the training and testing data sets. Overall the accuracy was 99.74% and 97.14% on the training and testing data respectively.
As a final test, I got my lovely wife to draw any number on the computer (she chose '4'). I then fed this into the neural network to get see if it could identify what she wrote:

Clearly there is something to these neural networks after-all.
Thank you for reading. Please check out Michael's book if you want to know more about neural networks. Also check out the code I wrote for this network on my Github.