Have you ever seen those kiosks at airports with smiley-faces on them? As you walk by, you hit a big button to express how you feel at the time. Well I was looking for a reason to play around with the Raspberry Pi Pico W, and thought that trying to recreate my own version of one of these would be a fun project.
The whole system is split into two parts: the physical kiosk, and the server backend/frontend. The physical kiosk connects to WiFi, logging all button presses both locally and sending them to the server backend. There's also a nice little web frontend to see some daily statistics on which buttons are being pressed.
The Kiosk

The Feedback Kiosk box and its internal wiring.
The brains, and main component, of the kiosk is a Raspberry Pi Pico W but to get all the features I wanted, I also included the Adafruit Adalogger. The Adalogger is a combo real-time clock and SD card adapter for the Pico essentially built for logging, exactly what is needed for the kiosk. Aside from those, I also picked up a few large push buttons off Amazon and a small wooden box from Walmart. I think the push buttons are targeted at people wanting to make their own Pop'n Music controller, but they worked well for this project.
The basic operation of the kiosk is pretty straightforward. It constantly waits for button presses and, when it detects a press, logs it locally to the SD card and uses WiFi to send it to the server for safer keeping. One of the cool features of the Pico is that it is multi-core. So, one core can constantly check for button presses while the other can handle the logging and HTTP requests. This has the advantage of the main loop never getting blocked by slow WiFi and we never miss a button press.
Another interesting feature I built into the kiosk is a simple webserver that allow users to change the WiFi connection settings. If the kiosk can't connect to a WiFi hotspot, it starts itself as its own access point. Connecting to this access point from a smartphone takes the user to simple webpage where they can supply an SSID and password. Pretty handy when moving it between different locations.
Alternatively, the kiosk can be started in offline mode by holding down the red button on boot. This will only log to the SD card and not try to use any wireless features.
The Server
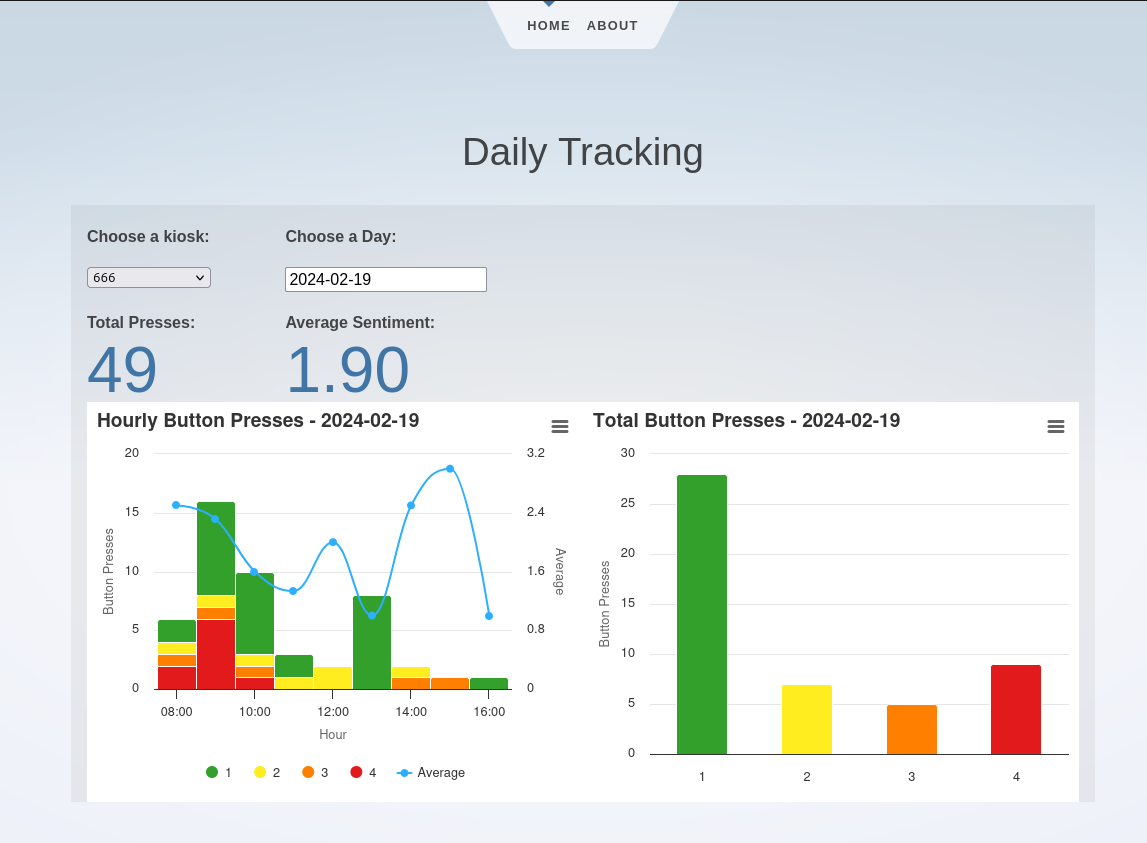
Screenshot of the Svelte webpage to view daily button presses.
For the server backend, I wanted to try programming something new decided to try writing it in Rust using the Actix web framework. I don't think this project was really large enough to get a good grasp on Rust, but it was a nice learning experience for sure. Normally, I would have used C and bittyhttp for a small project like this.
One thing I liked with Rust was its great package manager and compiler. It made it very easy to get whatever libraries I needed and statically cross-compile the whole application into a single executable. Then I could simply copy it over to the server actually running it. I know this is possible with other languages as well but Rust's package manager and compiler just made it so easy I really appreciated that.
Currently, there are only a few endpoints built into the backend: one to receive button presses, one to send back all button press data (for the frontend), and another to send the current time information to kiosk which is handy for setting the RTC.
As for the frontend, I stuck with Svelte, which I have use for several projects in the past. For simple cases like this one, I find that it makes things very easy and quick to get the behaviour that I want. My favorite feature of Svelte though is the ability to compile everything to static pages, meaning I don't need any other server components running aside from the backend.
Closing
Although this whole thing is very much a prototype, I think it would be really fun to deploy the feedback kiosk somewhere that is busy enough to get a lot of data. I'd really like to see how people's mood changes throughout the day, or even throughout a week.
Code for this project is also available on GitHub: https://github.com/cluoma/big_button
Thanks for reading!
